Rylan Schaeffer

Resume
Research
Learning
Blog
Teaching
Jokes
Kernel Papers
Failures
Min-p, Max Exaggeration: A Critical Analysis of Min-p Sampling in Language Models
by Rylan Schaeffer
1. Background
A few months ago, a Stanford PhD student approached me about Nguyen et al. (2024),
a preprint that introduced a new method for sampling from language models called min-p.
The paper was the 18th highest scoring submission at ICLR 2025
and was selected for an Oral presentation.
My friend had found min-p exciting, and wanted to see if he could improve on it.
After trying for 3 months, he felt like all sampling methods are roughly the same and that he could make any method
the winner by selectively presenting results.
I offered to help him establish strong baselines to better assess different sampling methods.
We ended up discovering what we believe are numerous and significant technical flaws throughout the original min-p paper.
We additionally discovered that the paper’s quantitative claims of widespread community adoption were unsubstantiated.
We then met with the authors to share our findings and discuss, leading the authors to unilaterally
(and in some cases, silently) change the ICLR 2025 Camera Ready manuscript after the review process had concluded.
This blog post complements our corresponding Arxiv manuscript
by offering a more chronological story as well as some personal viewpoints.
Table of Contents
- Background
- Issues with Human Evaluations:
- Human evaluators’ scores for a baseline were omitted and then silently re-added.
- Quantitative scores do not demonstrate
min-p’s claimed consistent superiority. - Qualitative human feedback fails to support preference for
min-p. - New human evaluations continue to showcase
min-pimproves neither quality, diversity or the tradeoff between quality and diversity.
- Issues with NLP Benchmark Evaluations
- Issues with LLM-As-A-Judge Evaluations:
- Issues with Community Adoption Claims
- Norm Violations During ICLR 2025 Camera Ready Process
- Discussion
- Acknowledgements and a Personal Comments
Our code is publicly available at https://github.com/RylanSchaeffer/KoyejoLab-Min-p-Sampling. Our W&B sweeps for the NLP benchmark evaluations are similarly publicly available.
2. Issues with Min-p’s Human Evaluations
We begin our investigation with Nguyen et al. (2024)’s human evaluations since human judgments are widely considered the gold standard for assessing language model outputs. We found three significant problems.
2.1. Human Evaluators’ Scores For a Baseline Were Omitted And Silently Readded
Nguyen et al. (2024) stated that human evaluators were used to evaluate min-p against a single baseline sampler, top-p:
“We conducted a comprehensive human evaluation focusing on creative writing. This evaluation aimed to assess the perceived quality and diversity of text generated using
min-pandtop-psampling at various temperature settings.”
Both the Oct 2024 Arxiv manuscript and the reviewed ICLR 2025 manuscript
manuscripts repeatedly stated that two samplers were considered, and results are presented only for min-p and top-p.
However, when examining the authors’ publicly posted data,
we discovered the data contained scores for a third sampler (basic sampling) that were collected but omitted without mention or explanation.
We publicly confirmed with the first author
that the data included basic sampling.
To the best of our knowledge, basic sampling goes unmentioned in both the
Oct 2024 Arxiv manuscript and the reviewed ICLR 2025 manuscript.
There is no mention or justification of these data being excluded.
After we flagged the issue, the authors added the omitted data into the Camera Ready manuscript’s Table 4 without changing their methodology or their results, and (as best as we can tell) without notifying the reviewers or the area chair. This change was made in the 15 Mar 2025, 04:01 revision after the ICLR 2025 review process had already concluded.
2.2. Quantitative Scores Do Not Demonstrate Min-p’s Claimed Consistent Superiority
Based on the human evaluators’ quantitative scores, Nguyen et al. (2024) concluded that min-p “consistently” outperformed top-p:
“Overall,
min-psampling consistently scored higher than top-p sampling across all settings. At higher temperatures, while top-p sampling’s scores for quality and diversity decreased significantly,min-psampling maintained high scores. A paired t-test confirmed that the differences in scores betweenmin-pand top-p sampling were statistically significant (p < 0.05).”
However, the quantitative data, especially when the omitted basic sampling scores are included, fail to support
this claim of consistent superiority. To briefly explain the human evaluation methodology, three samplers
(basic, top-p and min-p) were compared in six conditions: 3 temperatures \((1.0, 2.0, 3.0)\) and two diversity
settings (high and low) corresponding to specific choices of p.
Humans were asked to score the generated outputs based on two metrics: quality and diversity.
Participants were included in the analyses only if they passed attention checks.
We focused on the high diversity setting for two reasons:
- The main promise of
min-pis that it provides both high quality and high diversity outputs, whereas other samplers typically trade one off against the other. - The first author publicly told us to focus on the high diversity setting, writing that “the low [diversity] settings were quite experimental”.
Plotting the authors’ publicly posted data shows generally comparable performance across samplers, with average scores overlapping within 95% confidence intervals:
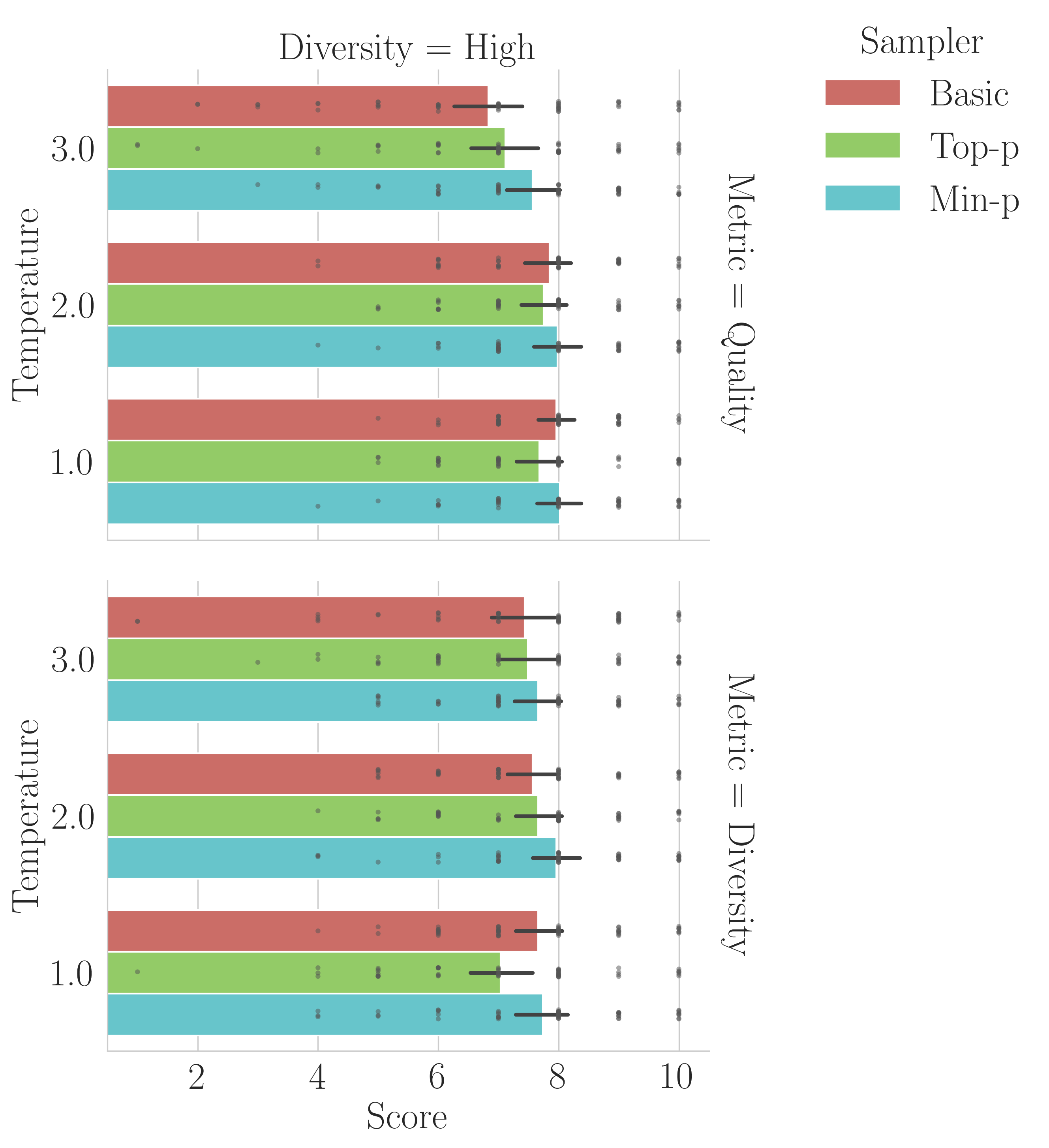
To rigorously assess the claim, we applied the statistical analysis implied by the original authors
(one-sided paired t-tests) comparing min-p against both basic and top-p sampling for the high diversity setting.
We conducted 12 one-sided paired t-tests for each metric (quality or diversity), temperature (\(1.0, 2.0, 3.0\))
and compared samplers (min-p versus basic, min-p versus top-p). In each test, we set:
- Null Hypothesis \((H_0)\):
min-p’s score is less than or equal to the other sampler’s score. - Alt Hypothesis \((H_a)\):
min-p’s score is greater than the other sampler’s score.
The results of the hypothesis tests are displayed below:
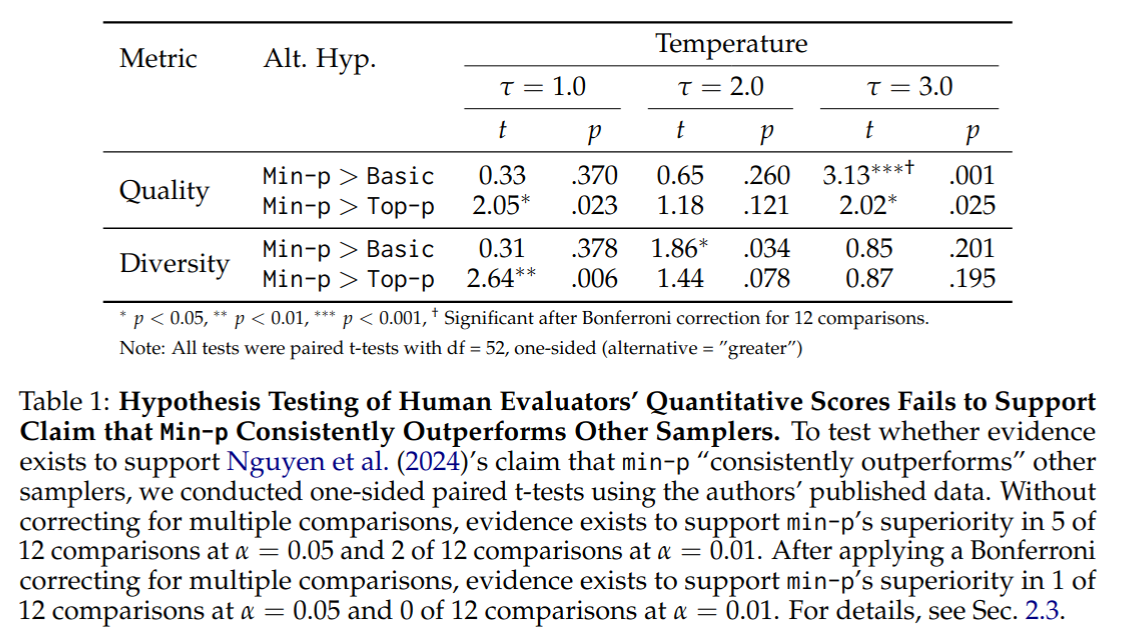
Without correcting for multiple comparisons, at \(\alpha = 0.01\), we found sufficient evidence to suggest min-p
outperformed the baseline in only 2 of 12 comparisons. After applying a Bonferroni correction for multiple comparisons,
at \(\alpha = 0.01\), we found insufficient evidence to suggest that min-p outperformed the baselines in any
of the 12 comparison.
Furthermore, given that the claim is that min-p is consistently better, we believe that a Intersection-Union Test
(IUT) may be the appropriate statistical test, where the alternative hypothesis is that min-p is better in all 12 comparisons
and the null hypothesis is the set complement of the intersection. Since the largest p-value of the 12 comparisons
is \(0.378\), we find insufficient evidence to reject the null hypothesis at both \(\alpha=0.05\) and \(\alpha=0.01\).
Therefore, based on the authors’ own collected data and standard statistical analysis, there is insufficient
evidence to support the paper’s central claim that min-p consistently outperforms baseline samplers
across all settings.
How did the authors reach a different conclusion? The paper lacks a precise description about how the authors
performed their statistical analyses (that reviewers should have asked for), but the authors
publicly clarified:
the data were pooled across all settings – metric (quality or diversity), temperature, diversity (high or low) –
and a single t-test was performed. The problem with pooling over all settings was that a poor performing hyperparameter
\(p\) was chosen for top-p in the low diversity condition that pulled top-p down by a significant amount.
Therefore, it was incorrect to claim that min-p outperforms top-p “across all settings.”
Even if we accept the result for low diversity outputs, the evidence fails to demonstrate that min-p
outperforms top-p for high diversity outputs, and these together contradict Nguyen et al. (2024)’s main
thesis that min-p best excels at producing high diversity outputs relative to other samplers.
Note: We aren’t sure why the human evaluations’ qualitative feedback and quantitative scores didn’t necessarily agree. Perhaps one explanation is that humans were asked to provide qualitative feedback at the end of the experiment after being told the full experimental design, and looking back, they could assess different sampling methods across multiple generations. But this is pure speculation.
2.3. Qualitative Human Feedback Fails to Support Preference For Min-p
In addition to quantitative measures, at the end of the study, Nguyen et al. (2024) asked human evaluators to
qualitatively specify which sampler(s) they preferred. The authors claim that the human evaluators’
qualitative responses support min-p over top-p.
However, when reading through the data, we discovered that their conclusion inaccurately characterizes human
evaluators’ qualitative responses. Readers are encouraged to review the authors’
raw data themselves.
We manually annotated the authors’ data,
and visualized our annotations of the human evaluators’ preferred samplers:
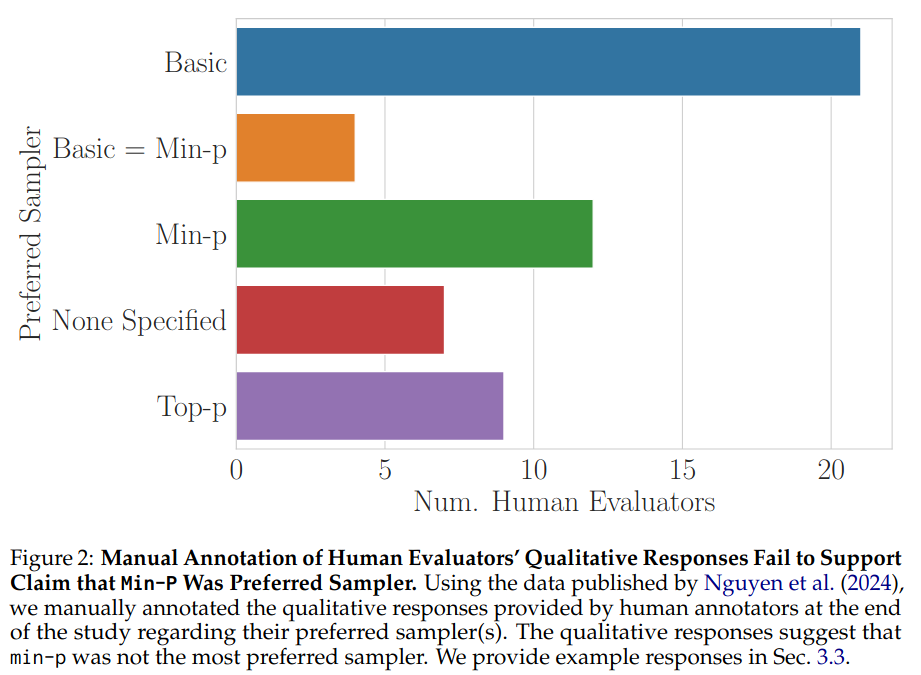
We make two observations:
- More human evaluators explicitly preferred
basicsampling than preferredmin-psampling Min-pwas only slightly preferred overtop-p.
Direct quotes from human evaluators favoring basic sampling underscores this point (Note: “Model A” in the study
was basic sampling; substituted below for clarity):
- ”[
basicsampling] on Temp 3.0 - High Diversity setting. The stories where [sic] more interenting [sic], felt more different …” - “I felt like [
basicsampling] was most diverse and most interesting with it’s [sic] descriptions of the characters and …” - ”[
basicsampling] was more engaging, it aroused my curiosity.” - ”[
basicsampling] provided more depth and easy to read for me and there was more diversity.” - ”[
basicsampling], they presented creative storytelling” - ”[
basicsampling]. From the very beginning the verbiage and descriptions were very creative and vivid. And each story was unique” - “I believe that [
basicsampling] has provided stories with more differentiation overall than the other two models…”
Therefore, the human feedback data posted publicly by the authors does not support their assertion that
human evaluators preferred min-p.
2.4. New Human Evaluations Continue to Showcase Min-p Improves Neither Quality, Diversity or the Tradeoff Between Quality and Diversity
After we shared our findings with the authors, they conducted a new human evaluation study to address our concerns. The new study made multiple methodological changes:
- Different sampler implementation: switched from applying temperature after truncation to applying temperature before truncation.
- Different distribution of human participants from Prolific.
- Different sampling hyperparameters for top-p: switched from 0.1 and 0.9 to 0.9 and 0.95.
- Different sampling hyperparameters for min-p: switched from 0.2 and 0.05 to 0.1 and 0.05.
- Different allotted reading time: increased from 30 minutes to 45 minutes.
- Different sampled text: 3 short paragraphs were replaced with a single complete story.
- Different rubric for human participants to evaluate sampled outputs.
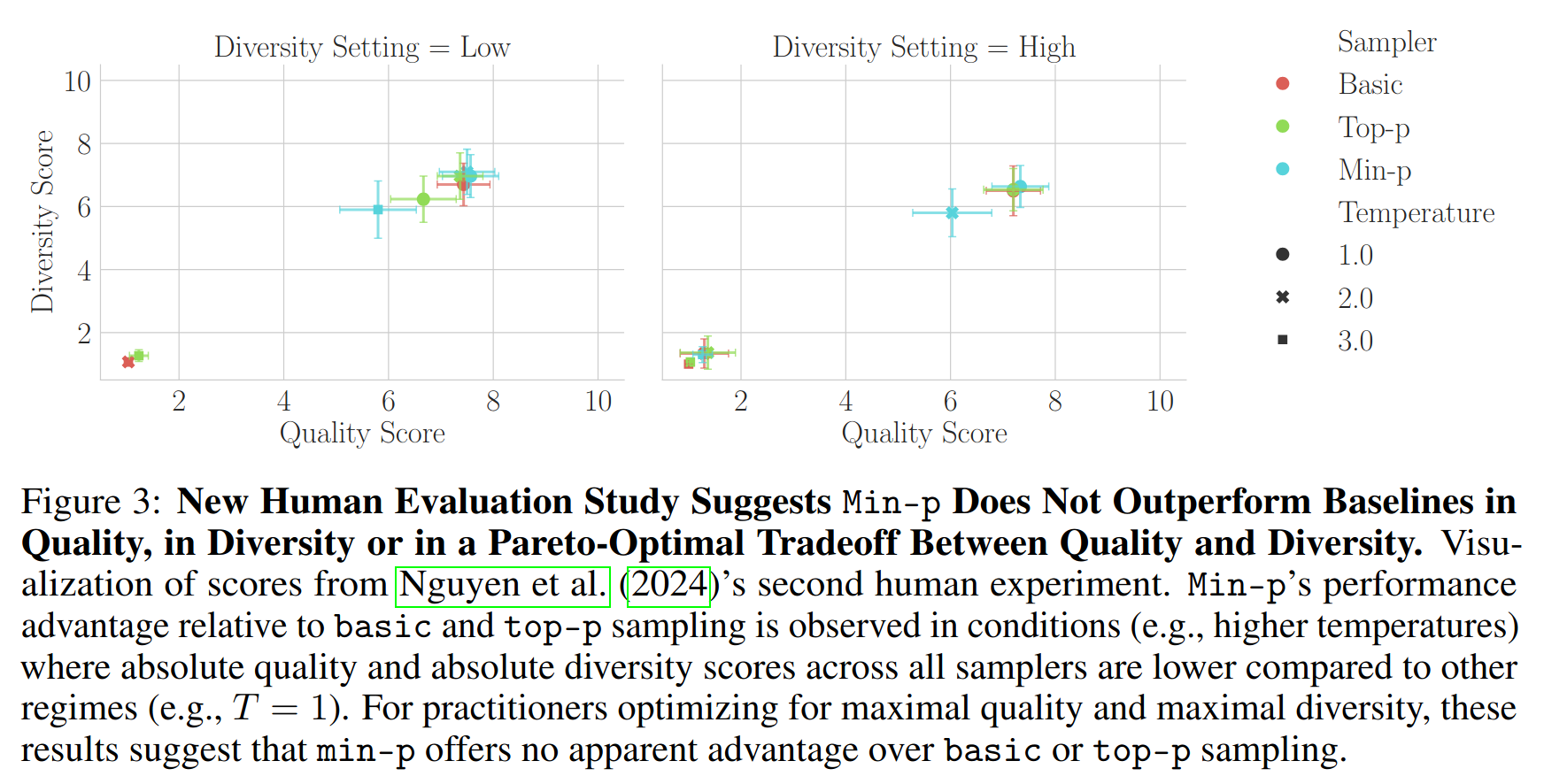
Regarding the new human evaluation data and results, we share two discoveries here: First, we believe one value is incorrectly reported: in Nguyen et al. (2024)’s Table 15, the average score of min-p at p = 0.05 and temperature T = 2 is reported as 7.80, but based on the authors’ publicly posted data, we believe the correct numerical value should be 5.80. Second, more generally, the new human evals again show that Min-p does not outperform baselines in quality, in diversity or in a favorable tradeoff between quality and diversity:
3. Issues with Min-p’s NLP Benchmark Evaluations
We next turn to the NLP benchmark evaluations presented by Nguyen et al. (2024). The authors evaluated several models on GSM8K with Chain-of-Thought and GPQA (5-shot), concluding broadly that:
“Min-p sampling achieves superior performance across benchmarks and temperatures.”
We investigated this claim through rigorous, large-scale experiments on one of these benchmarks, GSM8K, to determine
if min-p’s purported superiority holds under thorough hyperparameter exploration.
3.1. Thorough Hyperparameter Sweep on GSM8K Contradicts Claim of Min-p’s Consistent Superiority
To rigorously test the claim of superior performance “across benchmarks and temperatures,” we conducted an extensive hyperparameter sweep specifically on GSM8K, using EleutherAI’s LM Eval Harness for consistency with the original manuscript. We swept several models over a wide range of hyperparameters, significantly exceeding typical evaluation breadth.
- 9 Models: Qwen 2.5 0.5B, 1.5B, 3B and 7B; Mistral 7Bv0.1; Llama 3.1 8B and 3.2 3B; Gemma 2 2B and 9B.
- 2 Model Stages: Pre-trained (“Base”) and Post-Trained (“Instruct”).
- 4 Samplers:
basic,top-p,top-k,min-p. - 31 Temperatures: 0.0 (“greedy”) to 3.0 in increments of 0.1.
- 6 Hyperparameters Per Sampler: We chose six hyperparameters per sampler, except for
basicwhich has no hyperparameter beyond temperature. The hyperparameter values were taken from Nguyen et al. (2024)’s appendices and some were lightly edited to make them more spread out:basic: No hyperparameters beyond temperature.top-k: \(k \in \{ 10, 30, 50, 100, 150, 200 \}\).top-p: \(p \in \{ 0.99, 0.98, 0.95, 0.9, 0.8, 0.7 \}\).min-p: \(p \in \{ 0.01, 0.02, 0.05, 0.1, 0.2, 0.3 \}\).
- 3 Random Seeds for Sampling: \(\{0, 1, 2\}\)
To evaluate how performant each sampler is, we first averaged over the three sampling seeds and then conducted two complementary analyses:
Best-of-N Performance: We simulated finding the best score by sampling N hyperparameters (N=1 to 100) for each sampler, repeating 150 times, and averaging the maximum score found. This shows expected peak performance as tuning effort increases.
We found that when controlling for the hyperparameter search budget, for 15 of 18 models, the sampler made little
difference; for the remaining 3, top-p performed better.
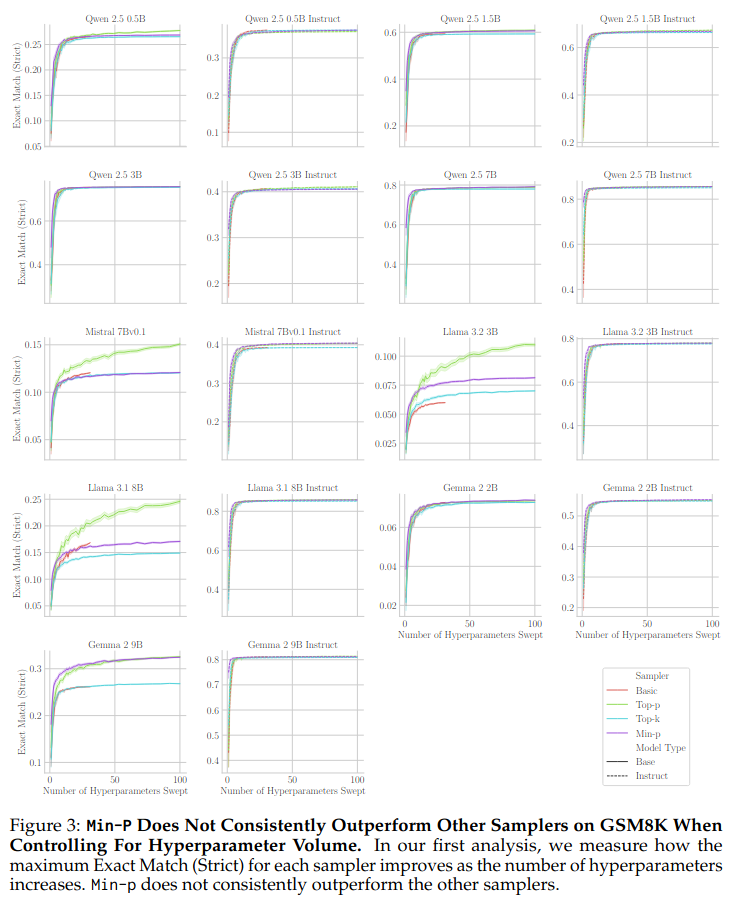
Performance Difference vs. Best Baseline: We calculated the difference between min-p’s best-of-N score and the maximum best-of-N score achieved by any other baseline sampler (basic, top-k, top-p), again averaging over 150 repeats for N=1 to 100. This directly measures min-p’s advantage (or lack thereof) when controlling for tuning budget.
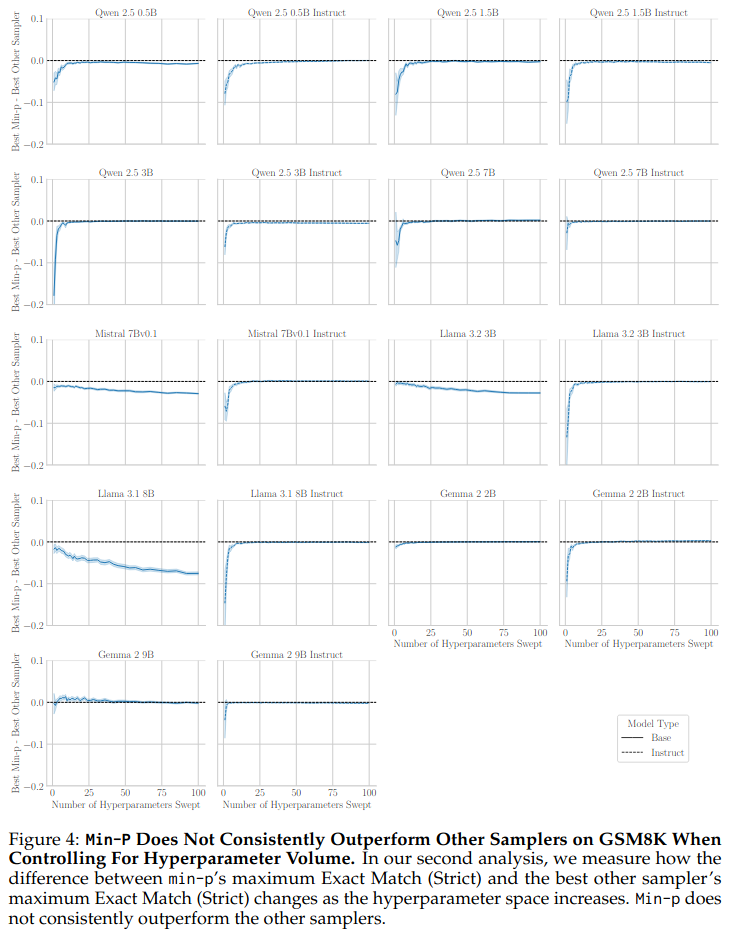
Both analyses yield a consistent and clear result: min-p does not demonstrate consistent superiority over other
standard sampling methods. The results suggest that most samplers achieve comparable peak performance on GSM8K once
given adequate tuning.
After we shared these initial results with the authors, they indicated that our use of the “Llama” prompt format for all models (copied from their provided replication Colab notebook) might be incorrect. The authors then edited their notebook to clarify that “Llama” formatting should be used only for Llama models.
To address this, we reran our sweep using the standard GSM8K prompt format.
The results were nearly identical, largely reinforcing our original findings, with one small exception:
min-p does produce higher scores on GSM8K for Gemma 2 2B IT and Gemma 2 9B IT.
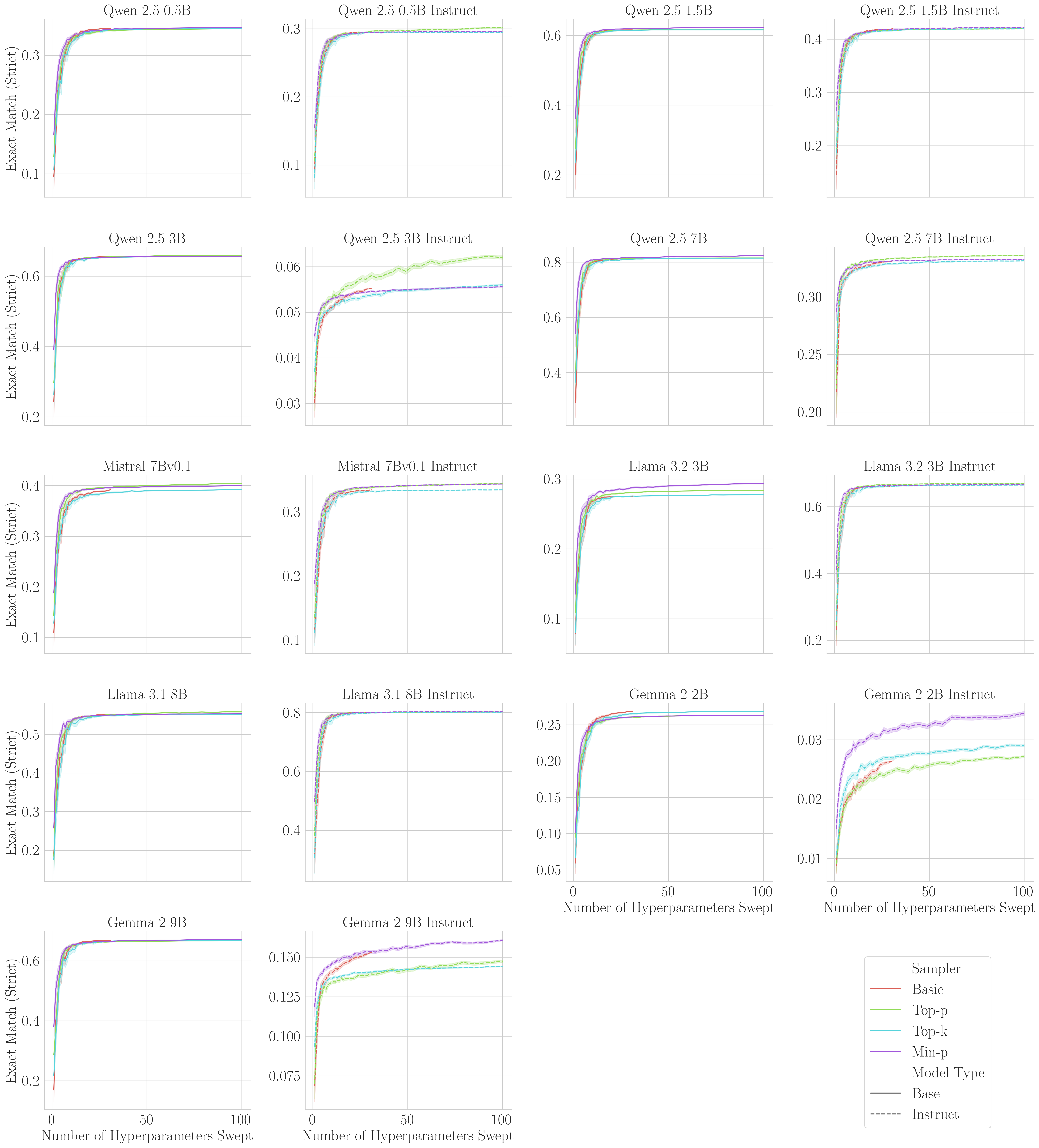
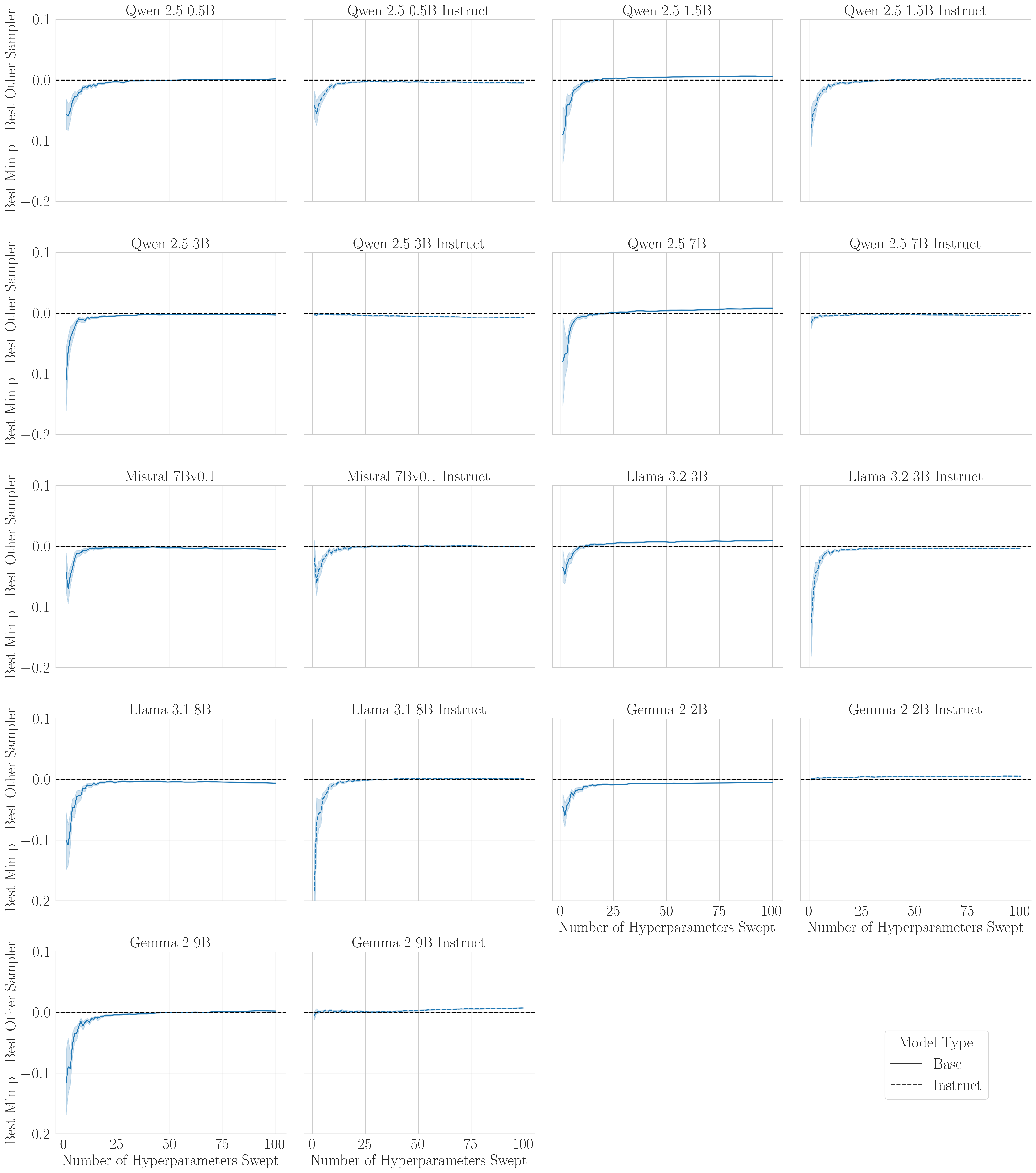
Again, we conclude min-p does not consistently outperform other samplers on GSM8K.
4. Issues with Min-p’s LLM-As-A-Judge Evaluations
To complement their human evaluations, Nguyen et al. (2024) employed LLM-as-a-judge evaluations, specifically AlpacaEval creative writing.
4.1. Under-Specified Methodology Prevents Verification and Interpretation
In the Oct 2024 Arxiv manuscript and the reviewed ICLR 2025 manuscript, the methodology is under-specified in several ways:
- There is no mention of which model(s) were sampled from.
- There is no mention of which model(s) served as the judge(s).
- There is no description of how hyperparameters were chosen or swept, raising a question of whether baselines received an equal opportunity.
- There are no error bars (or any notion of uncertainty) for the win rates. Thus, the reader is unable to decide whether the win rates are statistically different from chance (50.00%).
No scores data or code to create AlpacaEval scores were provided with the original GitHub repository. While drafting this manuscript, we became aware of ongoing work by the authors aiming to release code in a separate repository. Scrutinizing the preliminary results revealed two discoveries:
{kind=link}
Lack of Min-p Superiority: The scores show that min-p frequently fails to outperform top-p and basic
sampling, especially when accounting for standard error. We visualize the new data with 95% confidence
intervals (with horizontal offsets added for visibility):
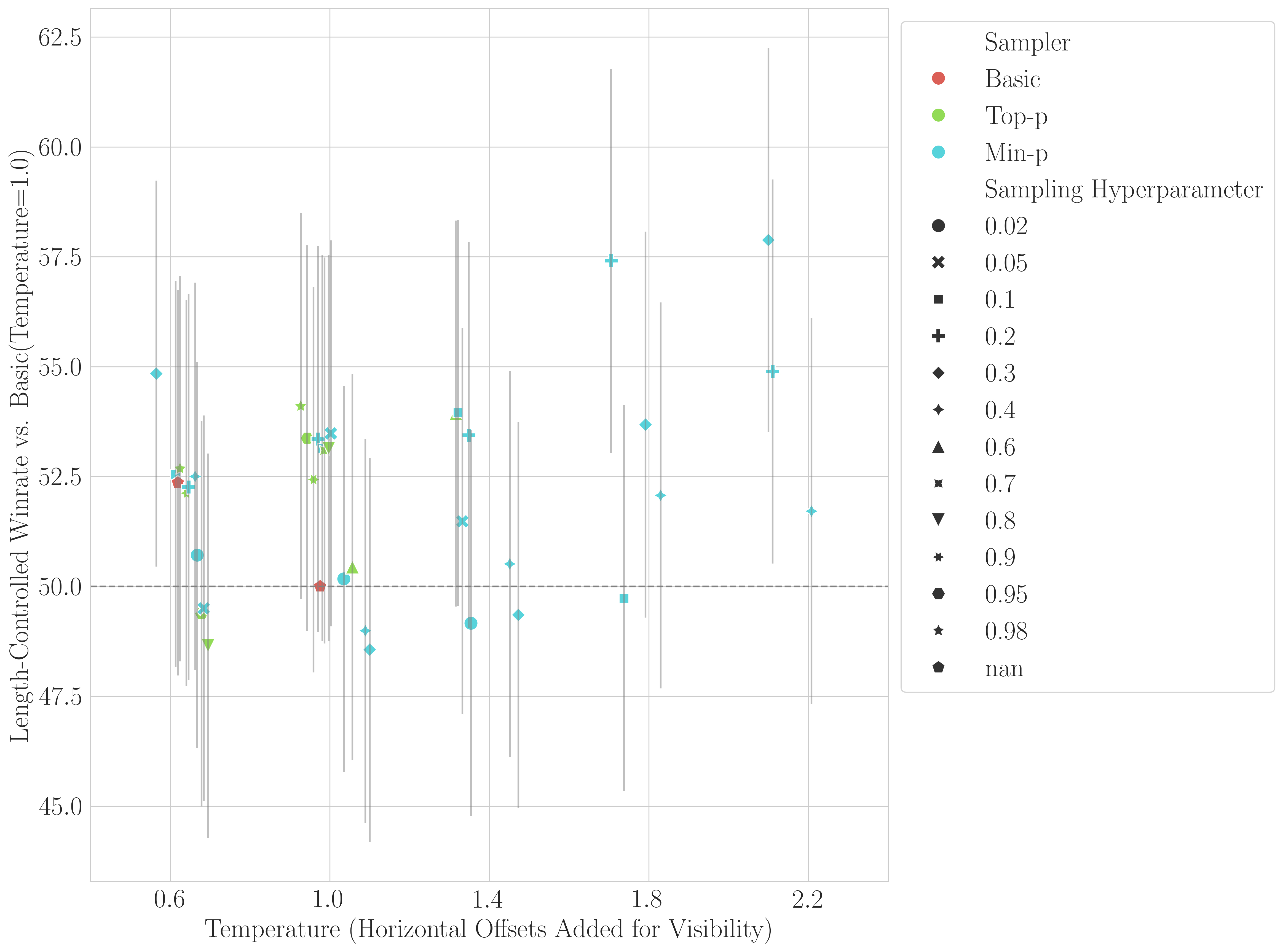
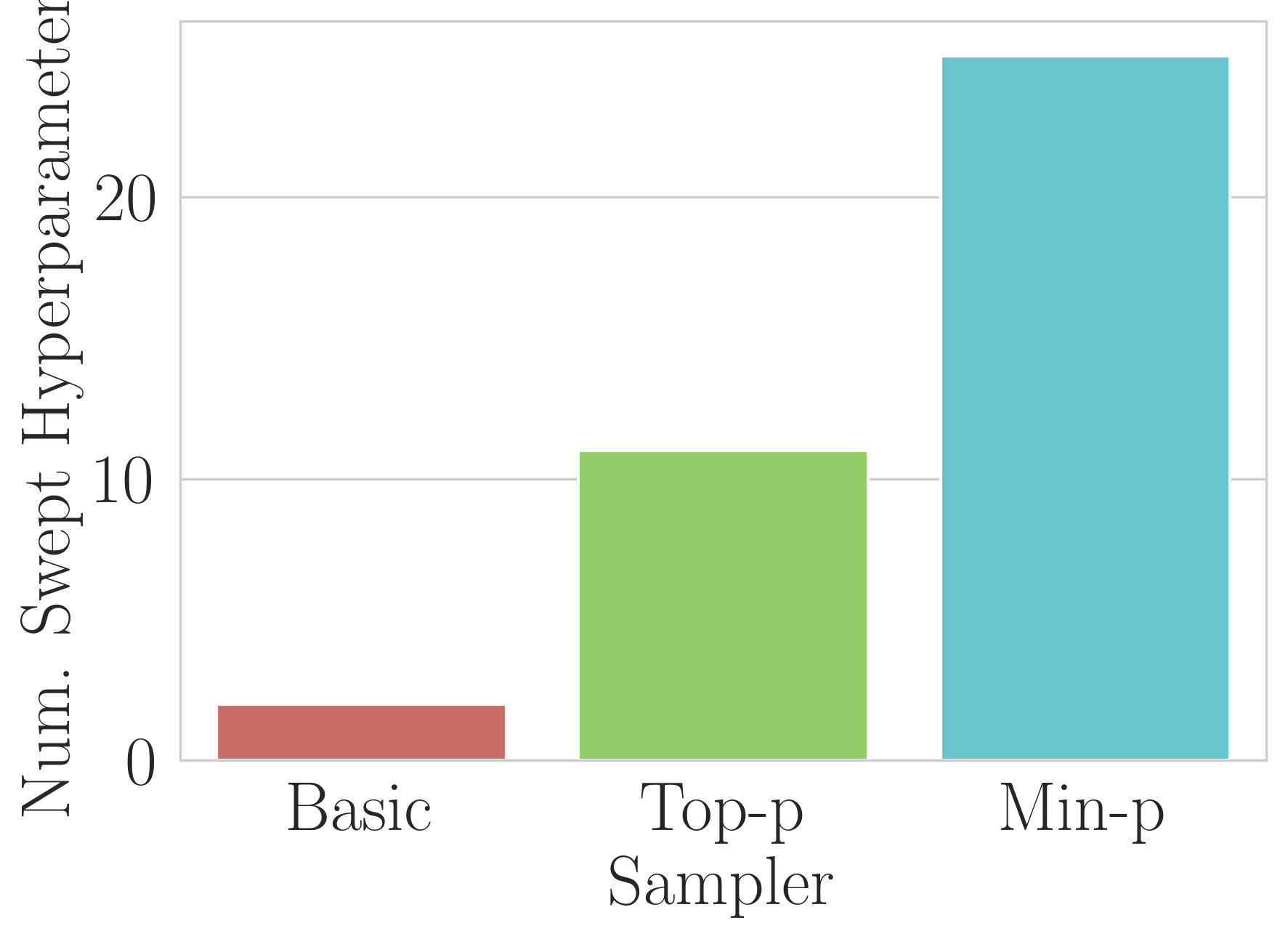
Unequal Hyperparameter Exploration: Min-p received significantly more hyperparameter optimization,
potentially tilting the scales in its favor. These counts are extracted directly from the authors’ posted data on GitHub.
{kind=link}
Furthermore, the experiment seems poorly designed. For those unfamiliar, AlpacaEval reports win rates between paired
comparisons. Instead of directly comparing min-p against other samplers, the authors compared each sampler against
a common fixed sampler: basic\((\tau=1.0)\).
This indirect comparison strategy seems odd, especially since directly comparing against min-p would offer
a clearer test of its superiority while using the same number of comparisons.
The authors’ design choice is additionally concerning because LLM-judge preferences are probably not transitive, as shown by
recent research.
That is, if sampler A beats sampler B, and sampler B beats sampler C, it does not necessarily follow that sampler A beats sampler C.
Therefore, comparing all methods to basic\((\tau=1.0)\) provides no reliable inference about min-p’s performance
relative to top-p or basic at other temperatures.
These under-specified aspects of the methodology, combined with its unusual experimental design, make drawing conclusions difficult.
4.2. At Least Two Win Rates Appear Selectively Reported in Table 3(b)
Analysis based on information publicly shared by the first author’s publicly posted Telegram link
provides evidence of selective reporting of scores in Table 3(b) that favors min-p:
- For
min-p: the reported win rate of 52.01 corresponds to p=0.05. A different hyperparameter (p=0.01) yields a lower win rate of 50.14. The higher score was reported formin-p. - For
top-p: the reported win rate is 50.07, corresponding to p=0.9. A different hyperparameter (p=0.98) yields a higher win rate of 50.43. The lower score was reported fortop-p.
This raises concerns about selective reporting and insufficient experimentation.
5. Issues with Min-p’s Community Adoption Claims
5.1. Claimed GitHub Repositories & Stars Were Unsubstantiated and Retracted
Beyond technical performance, Nguyen et al. (2024) made strong claims in their reviewed manuscript about
min-p’s widespread community adoption:
“Community Adoption:
Min-psampling has been rapidly adopted by the open-source community, with over 54,000 GitHub repositories using it, amassing a cumulative 1.1 million stars across these projects.”
This statement implies that 54k distinct repositories specifically utilize min-p, and that these repositories
collectively hold 1.1 million GitHub stars. These specific, verifiable numbers were highlighted by a reviewer and
the ICLR 2025 Area Chair as key evidence of the
paper’s impact.
We attempted to verify these figures through GitHub searches and analysis of major LM repositories known to incorporate
various sampling methods. Our investigation could not substantiate these numbers. We calculated the total combined
stars of major relevant open-source repositories (transformers + ollama +
llama.cpp + vLLM + Unsloth + mamba + SGLang + llama-cpp-python) amount to approximately 453k stars as of
March 2025, less than half the 1.1M stars claimed to be associated with min-p adoption alone.
When we inquired with the authors regarding the methodology used to calculate these numbers, the first author publicly stated they searched GitHub for “min-p”. We pointed out this clearly yields many false positives. After some additional back and forth, the authors were unable to substantiate those numbers and subsequently retracted both the 54k repo count and the 1.1M star count from the ICLR 2025 Camera Ready manuscript.
5.2. Revised Community Adoption Claim Still Inflates Min-p’s Impact
The ICLR 2025 Camera Ready now instead has a different statement of community adoption:
”[
Min-p] is now integrated in widely used frameworks such as Hugging Face Transformers, vLLM, and SGLang (Zheng et al., 2024), which collectively have accrued over 350,000 GitHub stars. This integration, coupled with extensive downstream usage (e.g., over 290,000 dependent repositories for Transformers alone), underscores the method’s practical impact (see Appendix A.5 for detailed statistics).”
While being integrated into transformers, vLLM and SGLang is indeed an accomplishment, the statement
misleadingly presents these libraries’ successes as min-p’s success rather than specifically measuring min-p’s usage.
This statement is analogous to publishing a book and then claiming credit for the entire library.
6. Norm Violations During ICLR 2025 Camera Ready Process
Peer review serves as the cornerstone of scientific progress, ensuring research stands up to independent and rigorous scrutiny. While camera-ready versions typically allow for minor corrections and formatting adjustments, substantive changes to methodology, results, or claims should undergo additional review. In this section, we document how after we communicated our discoveries to the authors, the authors unilaterally (and in some cases, silently) altered their camera-ready manuscript:
- The authors removed their claimed community adoption numbers (54k GitHub repositories, 1.1M GitHub stars) that were specifically emphasized by three reviewers and the Area Chair as reasons for accepting.
- The authors silently incorporated previously omitted human evaluations data for
basicsampling into Table 4, without corresponding updates to their methodology section or conclusions. - The authors conducted a new human experiment with a new methodology that produces more favorable outcomes for
min-p(Appendix C.2).
While we applaud the authors for being willing to update their research in response to our feedback, in our view, there are two problems: Firstly, post-acceptance alterations made without the scrutiny of reviewers fundamentally undermines the peer review process by compromising the manuscript’s contents as rigorously scrutinized and verified by independent experts. Secondly, while the authors did post a public comment on OpenReview acknowledging some changes, in our view, the comment is misleading and incomplete and is not an adequate substitute for peer review of the manuscript’s new contents.
7. Discussion
7.1. Scientific Conclusions
Our investigation leads to the conclusion that the main claims of Nguyen et al. (2024) are not adequately
supported by the evidence presented. The human evaluations, LLM-as-judge evaluations, and our extensive hyperparameter
sweeps on GSM8K all fail to demonstrate min-p’s consistent superiority over baseline sampling methods.
While min-p sampling represents a novel technical contribution to the field’s toolkit, our experiments
suggest that sampling methods (basic, top-p, top-k, and min-p) achieve comparable performance when given similar
hyperparameter tuning budgets.
7.2. What Went Wrong During the Review Process?
Nguyen et al. (2024)’s outstanding success in the ICLR 2025 review process - ranking as the 18th highest-scoring submission and achieving Oral presentation status - raises questions about the rigor of the evaluation. How was the submitted paper able to receive such recognition?
The reviews by Reviewers D38H, fwNb, and NZFq exhibited a lack of effort and a general lack of skepticism.
The reviewers failed to question basic methodological issues such as from which model(s) are being sampled
for the LLM-as-judge evals or missing/inadequate/improper consideration of uncertainty in presented results.
Reviewers uncritically accepted the authors’ claim that “over 54,000 GitHub repositories” were using min-p sampling,
when intuition or a quick GitHub search reveals cause for pause.
This unsubstantiated number was explicitly highlighted by Reviewer D38H and subsequently amplified by Area Chair 5p8J
as compelling evidence of the paper’s substantial impact.
The Area Chair may also have been inattentive, writing, “in the low temperature regime, [min-p]
provides a significant advantage;” in actuality, the paper specifically claims benefits in the high temperature regime.
7.3. Looking Forward
The issues identified in this case study reflect broader challenges in maintaining scientific rigor in rapidly growing machine learning venues. When papers with methodological flaws and unsupported claims receive prestigious recognition, they:
- incentivize others to produce less rigorous and disproportionately hyped research
- divert attention and resources from more rigorous work
- stymie the careers of more meticulous researchers
- pollute the scientific record
- undermine trust in AI research
Premier venues in ML such as ICLR should publicly acknowledge these shortcomings and outline a path to improve their respective review processes.
8. Acknowledgements and a Personal Comment
There are several people who contributed to improving the contents, figures, statistical analyses and writing of this investigation. I (Rylan) am hesitant to publicly thank them because questioning published work carries a high cost with almost no personal upside.
I want to briefly rebut a commonly-made criticism of doing critical work. Many believe that if a paper
has flaws or shortcomings, the field will eventually self-correct; while this statement is correct over a sufficiently
long timescale, it ignores the short-term cost born silently by the nameless others who try to build on the
flawed work. To share a personal story, my research career began with failing to reproduce work on
a research direction published in Nature and as
two
NeurIPS spotlights.
It was tremendously disheartening to be a young researcher accused of incompetence, laziness and low intelligence.
It wasn’t until my then-advisor kicked me out of his lab and I felt I had no future in research that I submitted
my refutation
of these prior works to NeurIPS 2022.
I will be forever grateful to my two colleagues on that paper who supported me and the scientific evidence at a steep
cost to themselves. When our paper came out, more than a dozen people privately messaged me, sharing how they too
had failed to replicate the same prior works. Their messages made me realize that the price of trusting the scientific community to
self-correct is the aspirations, careers and mental well-being of so many young researchers. After all, our story
here began because a PhD student spent three months trying to improve upon min-p before coming to me with their
self-doubts.
I encourage the ML research community to be more willing to publish negative or “critical” work, and I strongly believe those who can afford to pay a higher personal price for such work have moral and scientific obligations to do so on behalf of those who cannot.
tags: machine-learning - iclr-2025 - min-p-sampling - language-models - peer-review