Rylan Schaeffer

Resume
Publications
Learning
Teaching
Kernel Papers
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Authors: Sanh, Debut, Chaumond, Wolf (HuggingFace)
Venue: EMC @ NeurIPS 2019.
PDF: https://arxiv.org/pdf/1910.01108.pdf
Background
Parameters per language model have been rapidly increasing
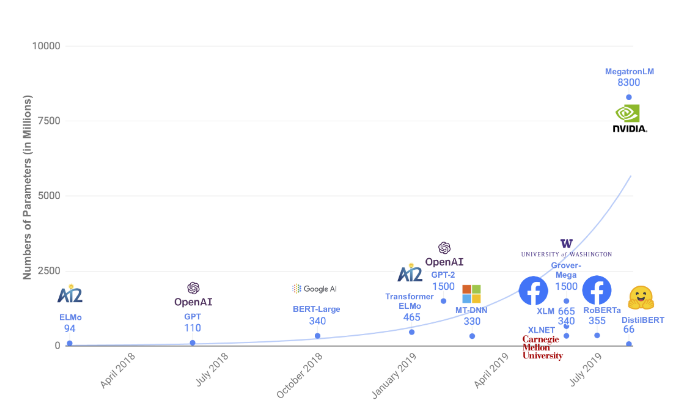
Idea
Distill pretrained transformer into smaller transformer that is 60% the size of the original. DistilBert is 60% faster at inference time. Student training loss is triple loss:
- Supervised training loss i.e. masked language modeling loss
- Cross entropy between student and teacher, with temperature parameter in softmax
- Cosine embedding loss between student and teacher hidden representations
- Initialize student by taking one out of every two layers
Results
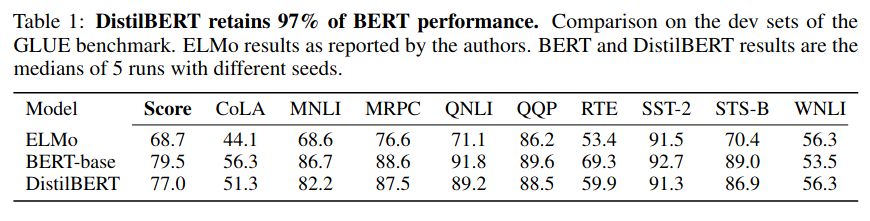
On GLUE benchmark, DistilBERT reaches 97% of BERT performance
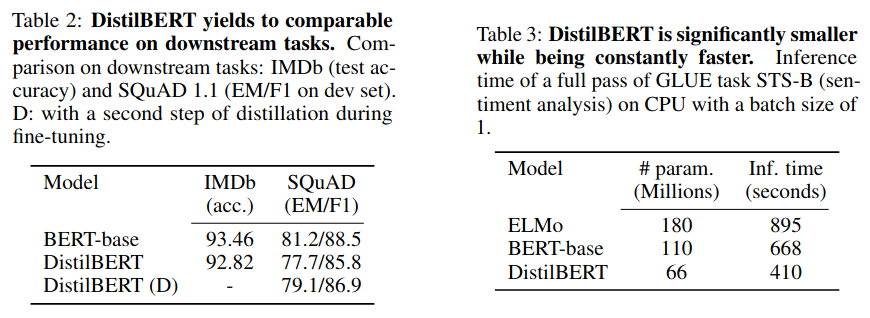
DistilBERT also performs well on downstream tasks and is faster
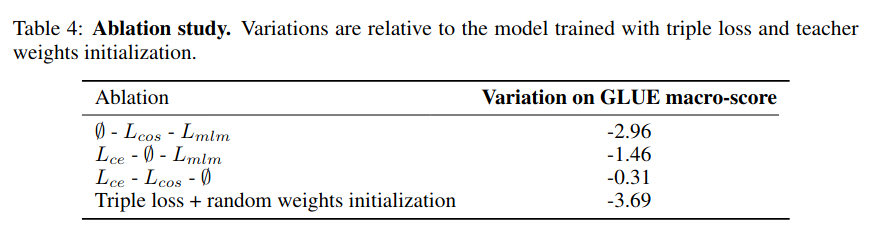
Ablation shows that the following changes have the biggest (negative) impact:
- Random weight initialization hurt most
- Student-teacher cross entropy
- Student-teacher representation cosine similarity
- Masked Language Modeling loss (i.e. the task loss used to train the teacher)
Notes
- TODO: Investigate what the following means: “We applied best practices for training BERT model recently proposed in Liu et al. [2019]. As such, DistilBERT is distilled on very large batches leveraging gradient accumulation (up to 4K examples per batch) using dynamic masking and without the next sentence prediction objective.”