I've found that the overwhelming majority of online information on artificial intelligence research falls into one of two categories: the first is aimed at explaining advances to lay audiences, and the second is aimed at explaining advances to other researchers. I haven't found a good resource for people with a technical background who are unfamiliar with the more advanced concepts and are looking for someone to fill them in. Frequently, papers will leverage common tools (e.g. recurrent neural networks, generative adversarial networks), and in order to clearly communicate those papers, I need to first explain those tools. In this post, I explain the titular tool - Variational Autoencoders (VAEs).
Understanding this paper would have been significantly harder without Carl Doersch's tutorial. My goal is to provide an abridged version of his tutorial, but I expect this post will end up being used just for my own reference.
Motivation
Kingma and Welling's paper opens with the following question: "How can we perform efficient approximate inference and learning with directed probabilistic models whose continuous latent variables and/or parameters have intractable posterior distributions?" At first glance, the question seems technically challenging, but it's worth taking time to understand.
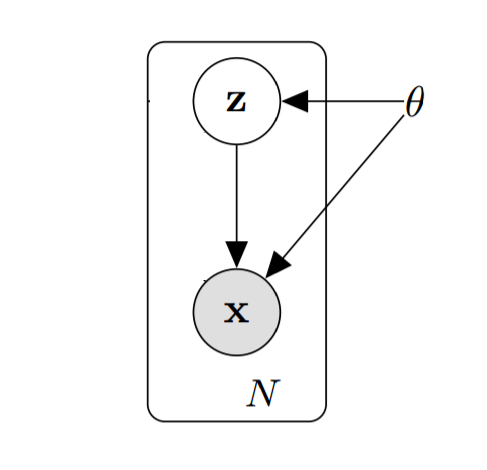
Let's start by understanding "directed probabilistic models." When we observe data, there is some underlying process that generated the data. We'd like to know more about this process, perhaps to understand its properties or to generate more data. We can learn about this process , and so we'd like to approximate the process. For simplicity, we'll assume that the process can be modeled using some parametric family of probability distributions (e.g. a normal distribution). More specifically,
If we assume that there is some parameter $\theta$ that determines the distribution $p_\theta(\mathbf{Z})$ over the hidden variables $\mathbf{z}$ - this is the horizontal arrow from $\theta$ to $\mathbf{Z}$. Then, together, the hidden variables $\mathbf{Z}$ and the parameter $\theta$ together determine the distribution $p_\theta(\mathbf{X} | \mathbf{Z})$ over the data $\mathbf{x}$
Background
Autoencoders
Let's start with an explanation of autoencoders. An autoencoder consists of two neural networks that work together to try to learn a compressed representation of the observed data. The first, called the encoder, attempts to find a lower dimensional representation of a data point, and the second, called the decoder, attempts to reconstruct the input data point given only the lower dimensional representation (hence the name autoencoder). Using a visual I stole from MultiThreaded, an autoencoder looks like this:

Intuition
VAEs are a type of autoencoder
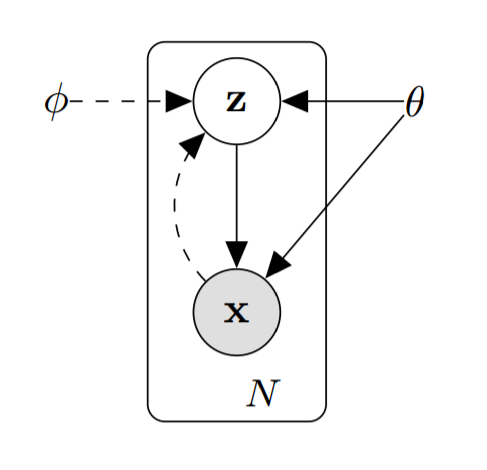
Mathematics
If it helps, break it down. We use the data $x$ and the approximation function $q_\phi(z | x)$ to determine which values of the latent variables $z$ most likely generated $x$. Then, we use the conditional probability $p_\theta(x|z)$
Experiments and Results
Discussion
Summary
Notes
I appreciate any and all feedback. If I've made an error or if you have a suggestion, you can email me or comment on the Reddit or HackerNews threads.