Comments on Shumailov et al. "AI models collapse when trained on recursively generated data." Nature 2024.
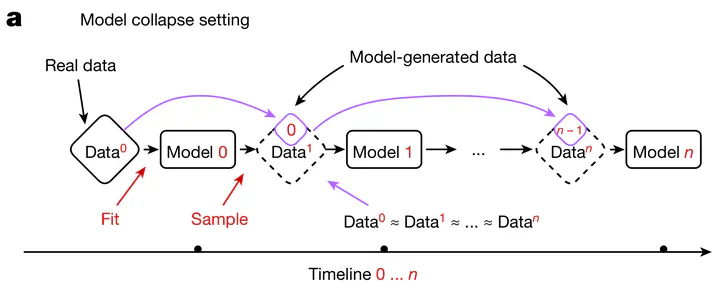 Image credit: Shumailov et al. Nature 2024
Image credit: Shumailov et al. Nature 2024Yesterday, I tweeted that model collapse appears when researchers intentionally induce it in ways that don’t match what is done in practice
Let me explain using the Shumailov et al. @Nature 2024 paper’s methodology as an example
Paper: https://nature.com/articles/s41586-024-07566-y
🧵⬇️
1/N
Model collapse arose from asking: what happens when synthetic data from previous generative models enters the pretraining data supply used to train new generative model?
I like Shumailov et al.’s phrasing:
“What happens to GPT generations GPT-{n} as n increases?”
2/N
Let’s identify realistic pretraining conditions for frontier AI models to make sure we study the correct setting
Amount of data: 📈 Llama went from 1.4T tokens to 2T tokens to 15T tokens
Amount of chips: 📈 Llama went from 2k to 4k to 16k GPUs https://x.com/NamanGoyal21/status/1815819622525870223
3/N
Quality of data: 📈 models are better performing, users mainly share higher quality outputs, pretraining data teams make better filters
Data Accumulates: 📈 This may seem obvious, but synthetic data from GPT4, Claude, Gemini, etc. is added to existing data (‼️)
4/N
To be clear, we’re concerned what will happen to frontier AI models pretrained on web-scaled datasets using industry best-practices
Thus, we want to study settings w/:
more data over time
Data for training a new model contains (much of) the original data
5/N
Let’s now turn to the Nature 2024 paper on Model Collapse
The 1st (theoretical) result studies repeatedly:
- fitting means and covariances to data
- sampling new data from Normal(fit mean, fit cov)
Result: iteratively doing this causes fit covariance to collapse to 0

6/N
Note - at each iteration, all prior data is thrown away ‼️
For the 2nd and 3rd (empirical) results, both similarly assume that (all or most) data is thrown away
7/N
The 2nd (empirical) result:
throws away all data after each iteration (not what people do in practice❌)
uses fixed dataset size (again, not what is done in practice ❌)
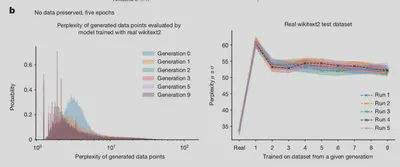
8/N
The 3rd (empirical) result keeps rand 10% of original data but replaces other 90% & uses same unrealistic decisions otherwise:
most data is still replaced ❌
dataset size is constant ❌
But note - by adding a little real data, they already see lower test perplexity!
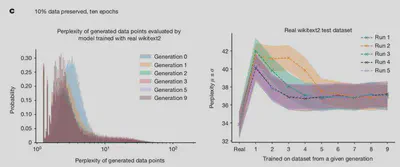
9/N
What did our COLM 2024 paper do differently? We
KEEP the full original dataset ✅
ADD new synthetic data to the overall accumulating data ✅
If we do this, i.e. data accumulate (right) no model collapse ✅
If we don’t, i.e., data are replaced (left) , model collapse ❌
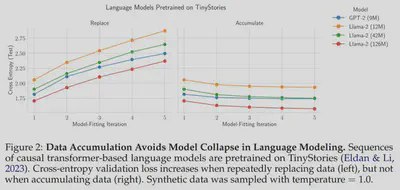
10/N
Our main finding is that if synthetic data is added to real data, then model collapse is mitigated
We show this holds across domains (text, vision, molecular conformation) & models (transformers, VAEs, diffusion)
We also prove this analytically in linear regression
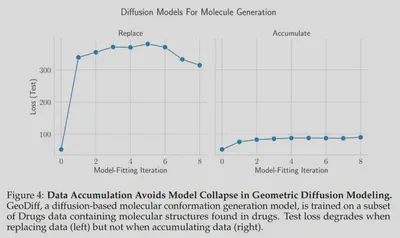
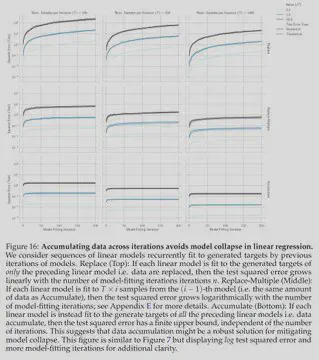
11/N
Let’s return to the theoretical result of Shumailov et al. 2024
What if the new synthetic data is instead added to existing data?
Last night, I ran new simulations in their exact setting
Data replaced -> Collapse ❌
Data accumulated -> Avoided ✅
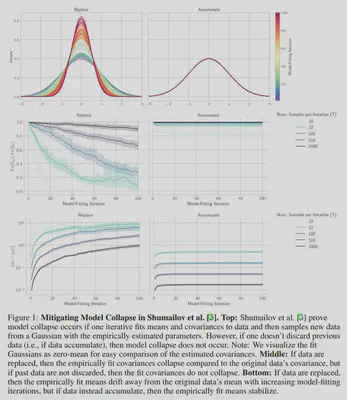
12/N
People are worried that widespread public usage of generative models might destroy future models, e.g.,
https://scientificamerican.com/article/ai-generated-data-can-poison-future-ai-models/
Because of the Nature paper, we were repeatedly asked by journalists: “How can we (humanity) make sure to avoid model collapse?”

13/N
The question is flawed. It presumes model collapse is a real and significant threat under current best practices
Based on the evidence I’ve seen, it isn’t
If there are other methodological questions about this Nature paper, our COLM 2024 paper or other papers, please ask!
13/N
@YangjunR @moinnadeem @sj_manning @gabemukobi
Hopefully this helps! Thanks for prompting me to put this together 🙏
If there are any remaining questions, please let me know!
14/N